
Machine Unlearning Governance
A Primer


Machine unlearning refers to the ability to remove specific data, concepts, or behaviours from an AI model after it has been trained, so that the model behaves as if it had never learned them. For boards, this is not a technical curiosity. It is a governance capability that sits at the intersection of privacy law, intellectual property, safety, and institutional credibility.
As regulators, courts, and the public increasingly expect AI systems to honor data deletion, content removal, and safety obligations, unlearning is becoming part of the control environment for AI—akin to cybersecurity, financial controls, or model risk management.
The core insight from recent research (including NeurIPS 2025) is simple but sobering:
Machine unlearning is possible, imperfect, and unavoidable.
Boards should therefore focus not on whether unlearning is “perfect,” but on whether it is defensible, auditable, and proportionate to risk.
What Machine Unlearning Is — and Is Not
At a high level, machine unlearning attempts to remove the influence of specific training data from a model without rebuilding the model from scratch. Conceptually, this is like removing certain ingredients from a finished recipe without re-cooking the entire dish.
It is important to distinguish unlearning from adjacent ideas:
Not data deletion: Deleting raw data does not remove its influence from trained models.
Not output filtering: Blocking certain responses does not mean the model has forgotten the underlying knowledge.
Not full retraining (necessarily): While retraining guarantees deletion, it is often impractical at scale.
Most real-world unlearning today is approximate. The question for boards is whether the approximation is acceptable for the risk class involved.
Why This Matters at Board Level
1. Regulatory and Legal Exposure
Privacy regimes such as GDPR explicitly recognize a “right to be forgotten.” Emerging AI regulations increasingly assume that models themselves—not just databases—can comply.
Boards should expect regulators to ask:
Can you remove personal data from deployed models?
Can you demonstrate that removal?
Can you explain residual risks honestly?
Failure here exposes firms to fines, injunctions, discovery costs, and supervisory intervention.
2. Intellectual Property and Content Risk
Generative models trained on scraped data face growing challenges around copyrighted text, images, styles, and proprietary data. Unlearning is becoming the least disruptive way to respond to takedown demands without scrapping entire systems.
3. Trust, Safety, and Institutional Credibility
An AI system that cannot forget undermines trust. Conversely, claiming perfect forgetting when it cannot be proven creates legal and reputational risk. Credibility lies in measured claims, documented trade-offs, and ongoing oversight.
How Unlearning Is Done: A Board-Level Comparison
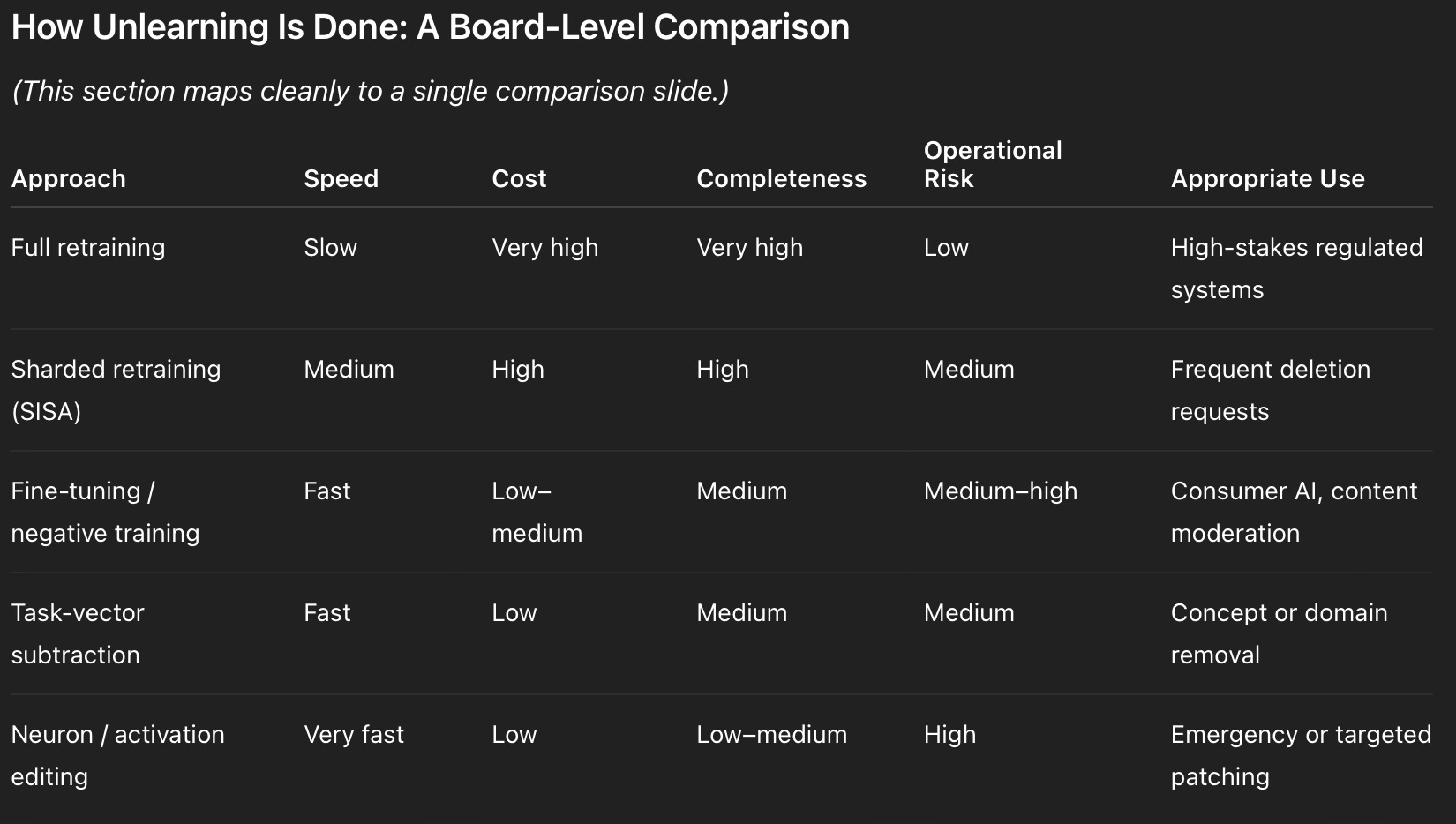
Key board takeaway:
Speed and cost rise with certainty. Unlearning choices encode risk appetite.
When Unlearning Is the Right Tool — and When It Isn’t
A simple decision logic applies:
Legally binding deletion request?
→ Favor retraining or sharded approaches.Reputational or IP risk without legal mandate?
→ Concept or task-level unlearning may suffice.Safety or misuse concern?
→ Unlearning may need to be paired with refusal mechanisms.Low-risk preference issue?
→ Output controls may be sufficient.
Unlearning should be treated as one instrument in a broader AI control framework, not a universal solution.
Concrete Real-World Patterns
Consumer AI Platforms
Approach: Periodic fine-tuning to reduce memorization.
Effect: Large reduction in recoverable personal data.
Residual risk: Some adversarial recovery remains.
Governance response: Combine with refusal policies and monitoring.
Financial or Insurance Models
Approach: Sharded retraining to ensure compliance.
Effect: Strong auditability, stable performance.
Cost: Meaningful but predictable.
Board logic: Cheaper than regulatory escalation.
Generative Media Systems
Approach: Concept unlearning for styles or identities.
Effect: High suppression under normal use.
Risk: Edge-case recovery via prompt engineering.
Mitigation: Red-teaming and post-deployment audits.
ROI: Why Boards Fund This
Cost of Not Acting
GDPR fines: up to 4% of global revenue
Litigation and discovery costs
Forced model withdrawal or retraining
Reputational damage and customer loss
Cost of Capability
SMEs: ~$100k–$500k annually
Mid-scale platforms: ~$500k–$2M
Foundation model providers: $5M+
Strategic Upside
Faster regulatory approvals
Stronger enterprise procurement positioning
Lower marginal cost per deletion request over time
Credible “compliance-ready AI” signaling
Board framing:
Unlearning is insurance against tail risk, with competitive upside for early adopters.
Risks Boards Should Explicitly Track
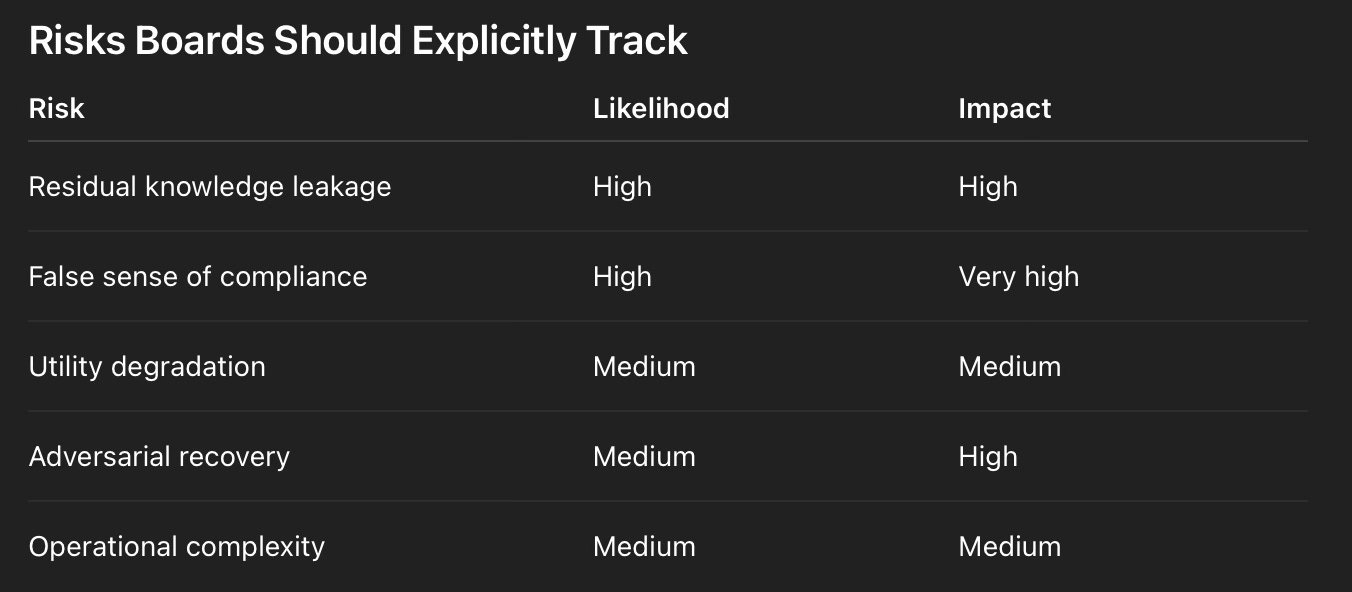
Mitigation Expectations
Stress-testing with perturbed inputs
Independent evaluation, not vendor self-claims
Layered controls (unlearning + refusals + audits)
Escalation paths to retraining when needed
Red Flags
Claims of “complete deletion” without caveats
No adversarial testing
No audit artifacts
Unlearning treated as a one-time fix
Vendor Evaluation: Board-Relevant Questions
Boards should ensure management can answer:
What unlearning methods are supported today?
How is forgetting measured and verified?
What failure modes are known?
Does forgetting survive fine-tuning and updates?
What documentation can regulators or courts review?
Capabilities checklist:
Data- and concept-level unlearning
Defined evaluation metrics
Adversarial testing
Compliance workflow integration
Clear retraining escalation
Final Governance Reframe
Machine unlearning is not about achieving perfect erasure.
It is about demonstrating:
Intent (we attempt removal),
Discipline (we test and document it),
Judgment (we choose proportional methods),
Accountability (we know when it is insufficient).
For boards, the question is no longer:
“Can our AI forget?”
It is:
“Can we govern forgetting in a way that regulators, courts, and the public will accept?”
That is the emerging standard—whether the technology is fully ready or not.
All Founding Subscribers receive a full Enterprise License to Risk Anchor included with their subscription.
That includes:
The full local package (HTML/JS/CSS) to run on your own infrastructure.
Unlimited assessments: Use it across as many models, business units, or portfolio companies as you need.
Ongoing upgrades: New modules (for example, Business Continuity, Drift Monitoring, or sector-specific controls) are included as they are released.

For more ideas consider purchasing “Shaping the Decade: Governance, Sustainability, and AI 2026–2036,” a guide for boards at the crossroads of governance, technology, and stakeholder capitalism. Available Here.

Tanya Matanda is a governance strategist bridging institutional oversight, AI governance, and fiduciary resilience. Her work supports boards, LPs, and regulators in designing governance systems fit for the AI era.
Copyright © 2025 Matanda Advisory Services
Research and Audio Supported by AI Systems
Wow, the insight that machine unlearning is possible, imperfect, and unavoidabel really hits; it makes me wonder how we practicly ensure user rights given its approximate nature.
Brilliant reframe on treating unlearning as insurance rather than a technical fix. I've seen orgs get bogged down in the 'perfect erasure' trap when what regulators really care about is documented intent and proportionate response. The comparison table between retraining vs fine-tuning is somethng I'll defintely use when explaining trade-offs to non-technical stakeholders.